One citekey to bind them
Since starting my PhD a just a couple of weeks ago, I already have a reputation amongst my office mates that I’m particularly structured and orderly about my stuff. If that judgement is correct or not I cannot say (I personally don’t find myself that orderly or structured). But I thought it might be interesting to write up the system that probably has had the biggest impact in my earning this reputation: the way I deal with the large number of articles and books that I (we all!) have to read and later reference in my work.
I’ve been working on and refinding this system for the better part of two years now, after getting super annoyed that I had a hard time remembering passages from texts or at least where to find them. Reading felt like a sysiphusian task: read a paper, cite one thing, forget everything (including that I read the paper), find the paper again, read it again, cite another thing, forget everything…and so on. Neither an efficient nor effective way to deal with incoming information. And needless to say: if the work you do is knowledge work, it’s paramount to have systems in place that make dealing with new and old knowledge as smooth as possible.
Asking around my scientist friends there emerged as many strategies as I asked people. Reference managers, word templates to summarise articles, elaborate Excel trackers, the varieties were endless and I naturally built my own system out of the many suggestions I encountered.
Dealing with the actual content of the papers and books that I read is a topic that is worthy of its own (long) post, so today I’ll introduce the backbone of my system: how I keep track of what I’ve read, when I’ve read it and where to find the actual paper/book/source.
Probably unsurprisingly, the main ingredient for my system is my reference manager. Since I’m a big friend of maximally compatible and plain-text based systems, I use BibDesk. While not the sleekest reference manager, BibDesk is ideal when writing in LaTeX (and/or Pandoc, another post in its own) and has all the features I need for my system. The most crutial feature for the context of this post is its automatic citekey generation and pdf filing functionality.
For every paper (or book, or other source) that I put into BibDesk, it automatically generates a citekey, i.e. a unique string of characters that identifies each source. I then only need to reference this key in my writing and all necessary information will be automatically included in the reference section at the end. The way I structure my citekeys is a very simple algorithm: the last name of the first author, the year the paper was published, and the first word of the title. When I then add a PDF to an entry, BibDesk automatically renames it to the citekey and files it in an appropriate folder on my computer. That way finding the pdf to any given paper is trivial, even if BibDesk should fail working. Importantly, I maintain only one BibTex file for all sources across all my research. I know some people maintain a separate database for each project, but I find this to be really cumbersome and resulting in duplicated effort: inputting source information, adding files, tagging them…I want to do this once for each paper and then never again.
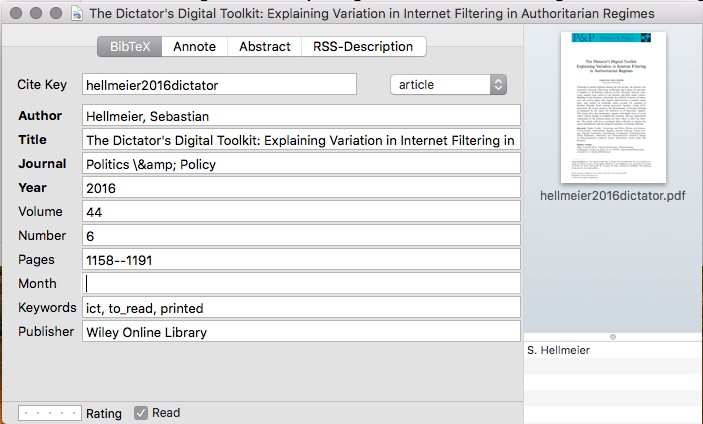
Crucially, I do the same filing as I do digitally with the source in its paper/dead-tree-form: every paper gets printed (I read better that way) and signed with the citekey. It also gets boxes for some meta information: have I read the source, when did I finish reading it, have I worked my notes into my Zettelkasten and did I go through the references and extracted all the relevant ones. You can see this in the following picture:

Once I’ve read and worked through the notes on a given source, it gets filed away into “cold storage”. This “cold storage” system are simply binders where sources are filed alphabetically, with dividers seperating them and again referencing the citekey and some of the meta information for easy retrieval should I want to look at the paper again or go through my original marginalia.

As you can see, this system is fairly simple and easy to understand. To me, it provides the perfect backbone to my reading process: any source I read is easily findable, needs to be only printed once (I actually used to print papers multiple times because I didn’t know where I had them lying around) and is ready to serve as small block in my knowledge.